Machine learning is now a vast and rapidly growing field. Machine learning, as a subset of Artificial Intelligence (AI), is the approach to learn from data, identify patterns and make decisions. Machine learning can help humans to solve tasks that are too complex for humans to code imperatively. In the history of machine learning, there were once huge setbacks due to insufficient computing capability. With the rise of cloud computing technologies and massive amounts of computational power, the power of machine learning has been unleashed.
The goal of Machine Learning is to make computers learn from the data that you give them. Instead of writing code that describes the action the computer should take, your code provides an algorithm that adapts based on examples of intended behavior. The resulting program, consisting of the algorithm and associated learned parameters, is called a trained model. Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Each type fits different goals.
In supervised learning, the model learns from labeled training data. In machine learning, data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it. Supervised learning can be classified into two subgroups: regression and classification. Regression is the problem of estimating or predicting a continuous quantity. One example is to predict income using social factors such as age, education, etc. Classification assigns observations into discrete categories rather than continuous quantities. The simplest case is binary classification which consists of two possible categories. One example is "Dogs vs. Cats" image classification.
Unsupervised learning is a type of machine learning algorithm that looks for hidden patterns or intrinsic structures in a dataset without pre-existing labels. There are several ways that unsupervised learning models are used. The most common example is cluster analysis, which is the process of finding similarities among unlabeled data and grouping them together. The clusters are modeled using a measure of similarity, through which we use unlabeled data to train a model by finding similarities in the data. We use the model to assign a new observation into a cluster of observations. For example, we may want to segment a population into smaller groups that have similar demographics such as level of education or age.
Reinforcement learning is useful in cases where the solution space is enormous or infinite, and typically applies in cases where the machine can be thought of as an agent interacting with its environment. The agent interacts with an uncertain, potentially complex environment to achieve a goal, following trial and error. Consider an agent that has an internal state which is put in an environment. The agent receives rewards for desired actions or penalties for undesired actions. The agent will update its internal state to maximize the total rewards. If there is a start state and an end state with multiple paths in between, reinforcement learning will find a path that would maximize the reward. Examples include self-driving vehicles or AlphaGo.
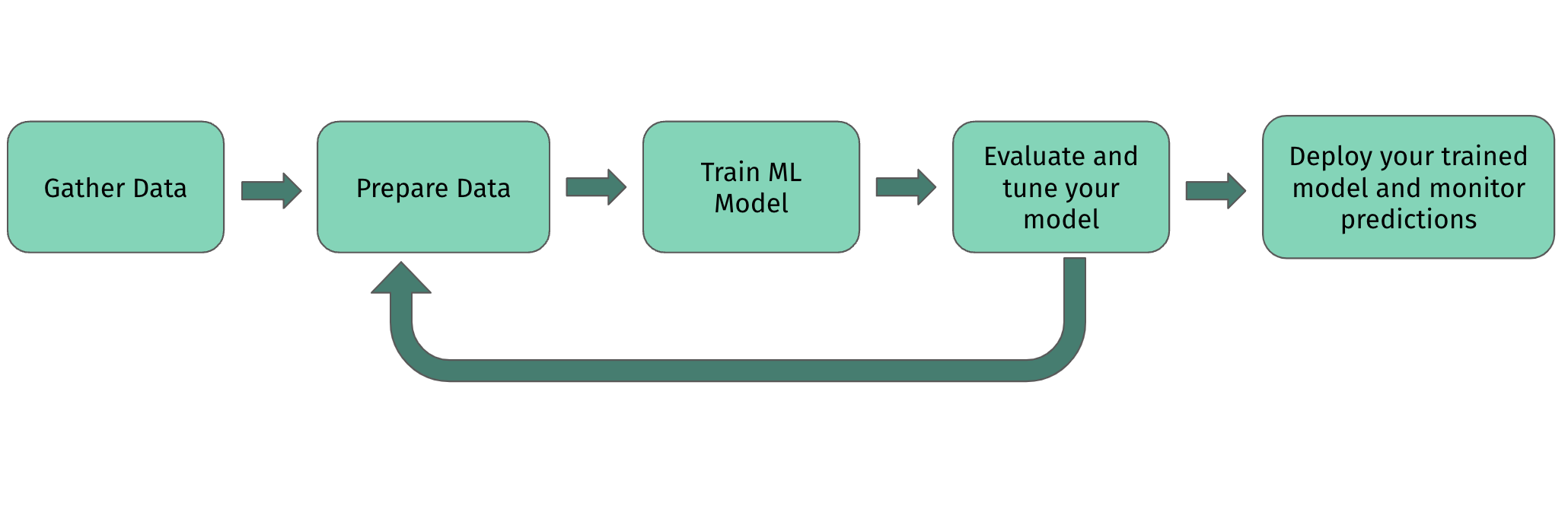
The diagram below gives a high-level overview of the stages in an ML workflow.
Figure 1: A high-level overview of the stages in an ML workflow.
Gather data
You must have access to a large set of training data that includes the attribute (called a feature in ML) that you want to be able to infer (predict) based on the other features. For example, assuming you want your model to predict the sale price of a house, you should have access to a large set of data describing the characteristics of houses in a given area, including the sale price of each house.
Prepare data
Once you've appropriately identified your data, you need to shape that data so it can be used to train your model. The focus is on data-centric activities necessary to construct the data set to be used for modeling operations. Data preparation tasks include data collection, cleansing, aggregation, augmentation, labeling, normalization and transformation.
Train your model
When training your model, you feed the model data for which you already know the value of your target data attribute (feature). You run the model to predict those target values for your training data, so that the model can adjust its settings to better fit the data and thus to predict the target value more accurately.
Evaluate and tune your model
Similarly, when evaluating your trained model, you compare the results of your model's predictions to the actual values. You can also tune the model by changing the operations or settings that you use to control the training process, such as the number of training steps to run. This technique is known as hyperparameter tuning. Through the evaluating and tuning process, reflect on your models and iteratively implement the above steps to improve your model.
Deploy you model and monitor predictions
Deploy your trained machine learning model to production, so that you can send prediction requests to the model. Monitor the predictions on an ongoing basis.
In the above pipeline, the majority of the time is spent in data preparation before modeling, since most machine learning algorithms require data to be formatted in a very specific way before they can yield useful insights. The quality of data is crucial to the quality of the machine learning model, for example, missing or invalid can result in less accurate or even misleading outcomes. Good data preparation produces clean and well-curated data which leads to more practical, accurate model outcomes. Therefore, let’s explore deeper about data to lay the foundation of a high–quality ML model.
Data has to be converted into appropriate representation so that the machines are able to learn the patterns within data. Understanding the different data types can help us identify correct preprocessing techniques & convert the data appropriately. Furthermore, it will also enable us to perform the best visualizations and uncover hidden knowledge. In this primer, we will introduce the following two classification of data to explore more: